Prometheus简介
Prometheus 是一套开源的系统监控报警框架。作为新一代的监控框架,Prometheus具有如下几个特点
- 多维度的数据模型
- 灵活和强大的查询语句(PromQL)
- 易于管理,prometheus是一个独立的二进制文件,不依赖分布式存储
- 采用pull模式利用HTTP采集数据
- 有多种的可视化图形界面(目前推荐使用Grafana展示数据)
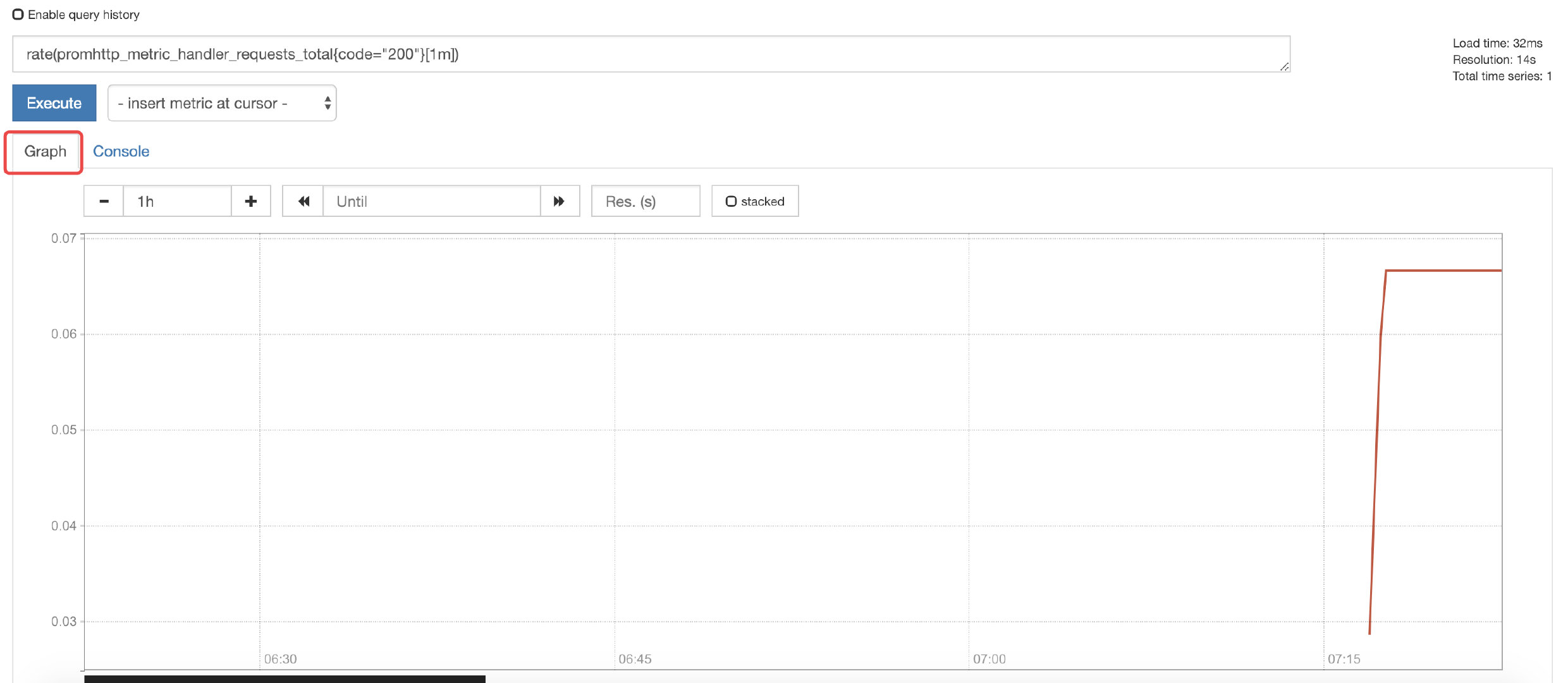
prometheus的架构如下图所示
prometheus的主要工作流程如下
- prometheus serve定期从job pull metric,或者接收来自Pushgateway的metrics
- prometheus将获取的metric存储在本地,并根据配置的alert rule向Alertmanage发送告警信息
- Alertmanage根据配置,对接收的告警信息进行处理,发出相应的告警
- 可视化采集的数据
Prometheus相关概念
instance
一个单独采集的目标(target),一般对应一个进程
job
一组相同类型的instance
web-api部署在多台实例上,prometheus会从每个实例上去采集数据
job: web-api
instance x.x.x.x:port1
instance x.x.x.x:port2
sample
实际的时间序列,每一个时间序列包含一个float64的值以及一个毫秒级的时间戳
metric
prometheus有4中metric,可以将metric理解为数据模型,metric的格式如下
<metric name>{<label name>=<label value>,...}
label
标签,用来表示采集数据的维度,例如有个指标为http_request_total表示所有http请求的总数,则http_request_total{method=”POST”}则表示请求方式为POST的请求总数,其中method就是label
Prometheus安装配置
下载prometheus,解压安装包
tar -zxvf prometheus-2.6.0.darwin-amd64.tar.gz
cd prometheus-2.6.0.darwin-amd64
启动
prometheus安装包下有一个二进制文件,叫prometheus,之前运行该文件,即可启动prometheus server
./prometheus --help
配置
prometheus的配置文件为prometheus.yml,内容如下
global:
scrape_interval: 15s # prometheus server 从instance拉取metric的间隔
evaluation_interval: 15s # prometheus server检测alert rule的间隔
scrape_timeout: 10s # proemtheus server抓取数据的超时时间
# Alertmanager 配置
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
# 告警规则
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
# 抓取对象配置
scrape_configs:
# 全局唯一的名称,用来标识一个job
- job_name: 'prometheus'
# 该job对应的所有instance
static_configs:
- targets: ['localhost:9090']
Metric
Counter
对数据进行累加,数据只会递增,例如http请求数,错误个数
Guage
可以对数据进行加减,例如温度,线程数量
Histogram
可以理解为柱状图,依据事先设置的阈值,对采集数据进行分类统计,适合统计的指标如response time,request size等
Histogram具有3个指标值
<metric_name>_bucket 对应分桶的条数
<metric_name>_sum 采集数据求和的值
<metric_name>_count 采集条数
下面以实例来说明上述三个指标,例如对response time进行统计,总共采集了3条数据,分别是
100ms,200ms,120ms
则以下三个指标分别表示
response_time_bucket{le=120}=2, response time小于等于120ms的数据有两条
response_time_sum=(100+200+120)=420 对所有的response time进行求和
response_time_count=3 总共采集了3条数据
Summary
与Histogram类似,最大的区别在于Summary可以精确的统计百分位的值,例如90%的响应时间低于200ms
summary也有三个指标
<metric_name>{quantile="<q>"} 0=<q<=1 百分位位于q的值
<metric_name>_sum 采集数据求和的值
<metric_name>_count 采集条数
Histogram VS Summary
- 都包含<basename>_sum,<basename>_count
- Histogram 需要通过 \
_bucket 计算 quantile, 而 Summary 直接存储了 quantile 的值。
Prometheus实例演示
启动prometheus
./prometheus --config.file="prometheus.yml"
启动成功之后可以在localhost:9090上查看对应的metric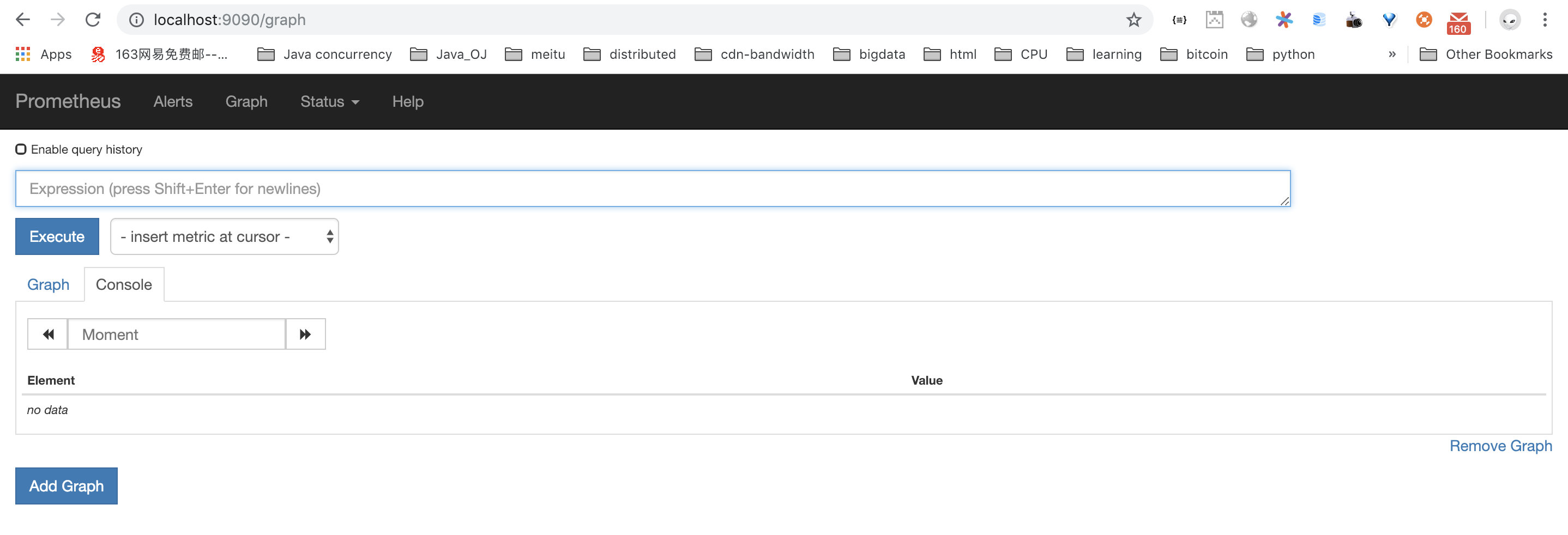
查看对应的指标
在输入框中输入指标名称,即可看到对应指标的值
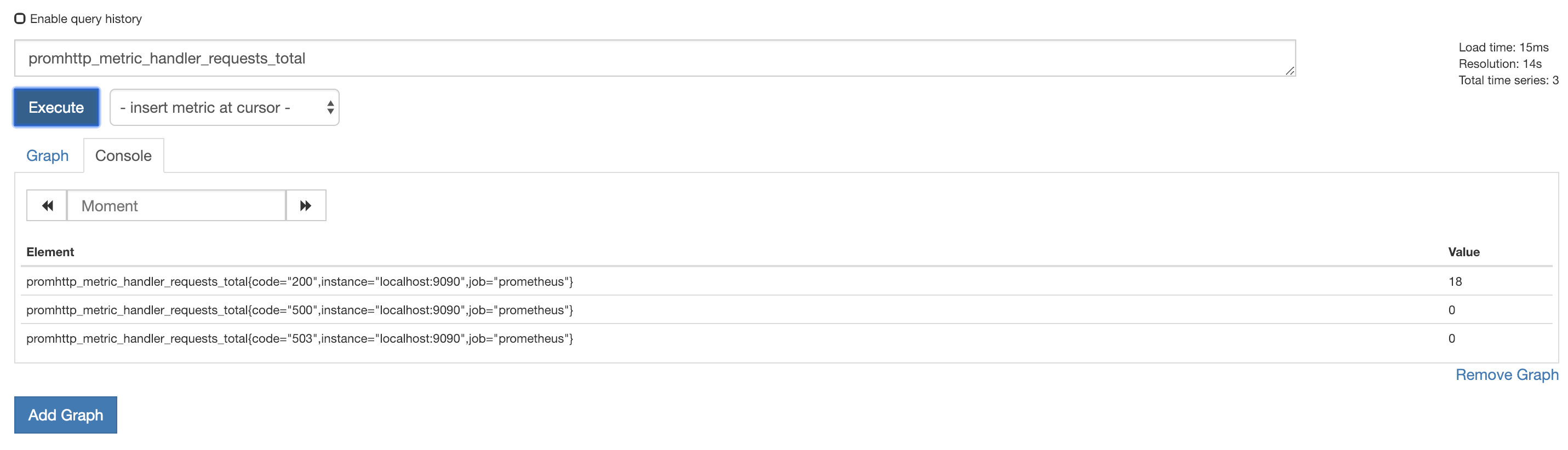
可视化指标
选择graph标签页,即可将对应的数据可视化,例如查看http请求code为200的QPS
rate(promhttp_metric_handler_requests_total{code="200"}[1m])