Prometheus 1.x VS Prometheus 2.x
1.0版本与2.0版本最大的改变之一就是存储引擎,1.x版本使用的是LevelDB,2.x使用的是TSDB,性能上有较大的提升,以下是官方对比数据
- 与 Prometheus 1.8 相比,CPU使用率降低了 20% - 40%
- 与 Prometheus 1.8 相比,磁盘空间使用率降低了 33% - 50%
- 没有太多查询,平均负载的磁盘 I/O<1%
Prometheus 存储
本地存储
Prometheus将两个小时的数据存储在一个目录底下,目录包含chunk(存储时间序列样本),meta(存储元数据),index(存储metric名称以及label)
数据会先缓存在内存中而不会立刻持久化到磁盘中,因此Prometheus采用write-ahead-log机制,当prometheus server发生异常,重启之后会根据日志重新加载数据。
通过API删除数据,数据先保存到tombstone文件,而不是立即从磁盘删除
./data/01BKGTZQ1SYQJTR4PB43C8PD98
./data/01BKGTZQ1SYQJTR4PB43C8PD98/meta.json
./data/01BKGTZQ1SYQJTR4PB43C8PD98/index
./data/01BKGTZQ1SYQJTR4PB43C8PD98/chunks
./data/01BKGTZQ1SYQJTR4PB43C8PD98/chunks/000001
./data/01BKGTZQ1SYQJTR4PB43C8PD98/tombstones
远程存储
prometheus可以与远程系统进行如下交互:
- prometheus可以通过remote_write写入数据
- prometheus可以通过remote_read读取数据

目前prometheus是通过HTTP协议传输数据,未来可能会使用gRPC。
采用远程存储时,prometheus进行查询时,会从远端拉取所需的数据,然后进行相应的处理,因此可靠性不能保证。目前PromQL是不支持分布式查询。
目前支持prometheus远程存储的数据源如下:

Prometheus Federation
Hierarchical federation
这种方式相同job的不同instance分布在不同的prometheus上,高一层级的prometheus server从低层级的prometheus server查询数据。
这种方式适合于某个job收集metrics过多,单台prometheus无法负荷时,可以利用这种方式对job的instance进行水平扩展,将不同的instance拆分到不同的prometheus中,在由全局的prometheus来收集聚合数据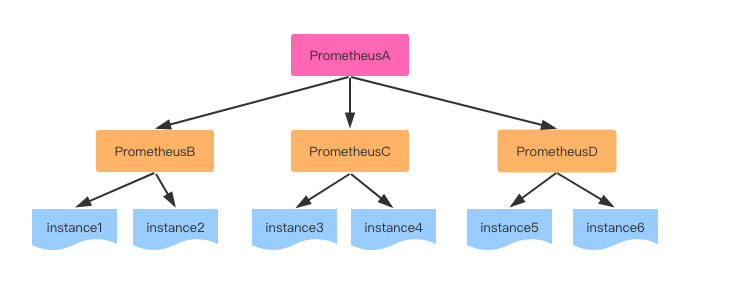
Cross-service federation
这种方式是以service维度来拆分prometheus,在由全局的prometheus来收集聚合数据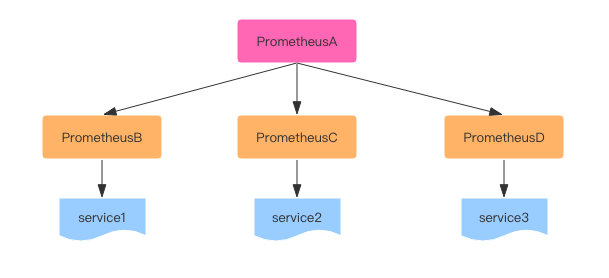
Federation的优缺点
优点:数据集中式管理,告警,不需要为每个prometheus实例管理数据
缺点:数据集中化,网络可能会延迟。Federation没有解决数据单点问题
Recording rules
recording rule类似于Influxdb的CQ,可以在后台处理配置的表达式,并将表达式的结果存储起来。recording rule主要目的是为了提前计算一些复杂运算结果,提供查询效率。CQ的主要目的在于聚合数据,从而通过不同的RP策略来保存数据
groups:
- name: example
rules:
- record: job:http_inprogress_requests:sum
expr: sum(http_inprogress_requests) by (job)
其中record表示指标的名称,expr则是指标的表达式
prometheus高可用部署
基于HA
部署多台prometheus server(一主一从),并采集相同export的指标。
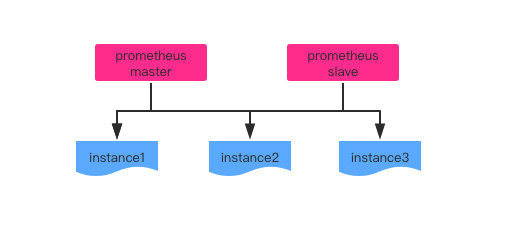
基于HA模式只能确保prometheus服务可用性问题,但是不解决prometheus server之间数据一致性问题已经持久化问题(数据丢失无法恢复)。
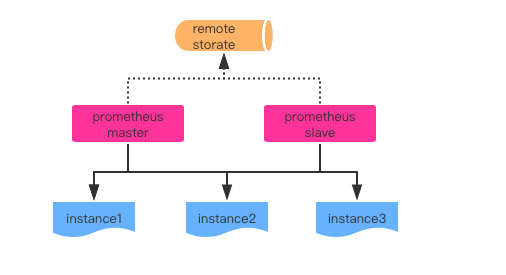
基于HA + 远程存储
在HA的基础上通过添加remote storage,将监控数据存储到第三方存储服务上。既解决了服务可用性问题,同时也确保了数据的持久化
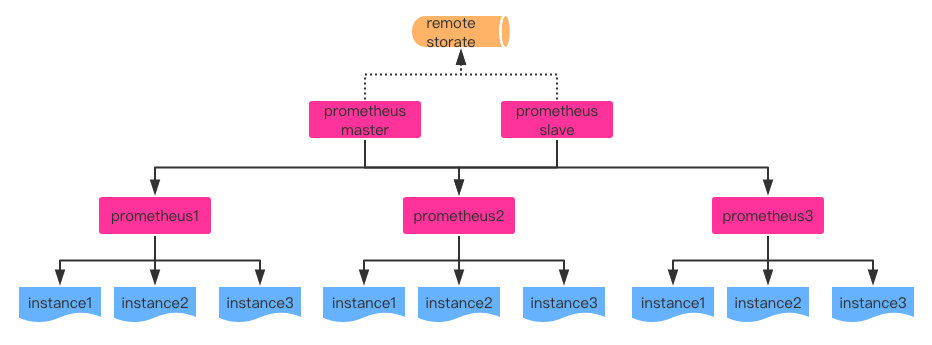
基于HA + 远程存储 + 联邦集成
当单台prometheus需要处理大量的采集任务时,可以使用prometheusde联邦的方式,将采集任务分割到不同的prometheus实例中。
三种方式对比
| 部署方式 | 使用场景 |
|---|---|
| 基于HA | 监控规模不大,prometheus server不会经常发生迁移,并且数据保存周期较短 |
| 基于HA + 远程存储 | 监控规模不大,但要求监控数据持久化 |
| 基于HA + 远程存储 + 联邦集成 | 单数据中心,并且采集指标量很大,此时prometheus的性能瓶颈主要在于大量的采集任务 |
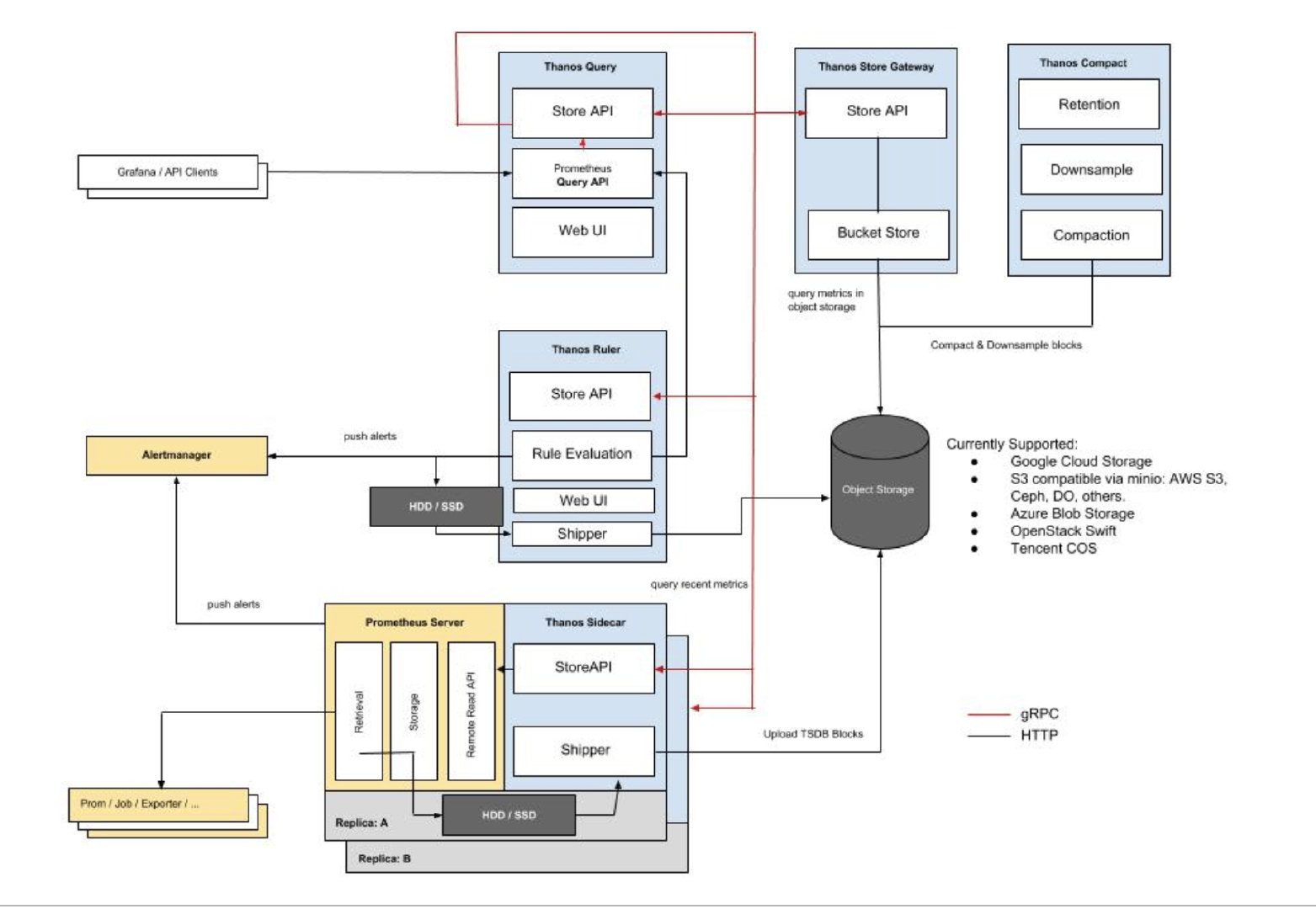
Thanos
thanos是开源的大规模Prometheus集群解决方案,它的设计目标如下
- 全局的查询视图
- 不受限的数据存储
- 高可用性
thanos的架构如图
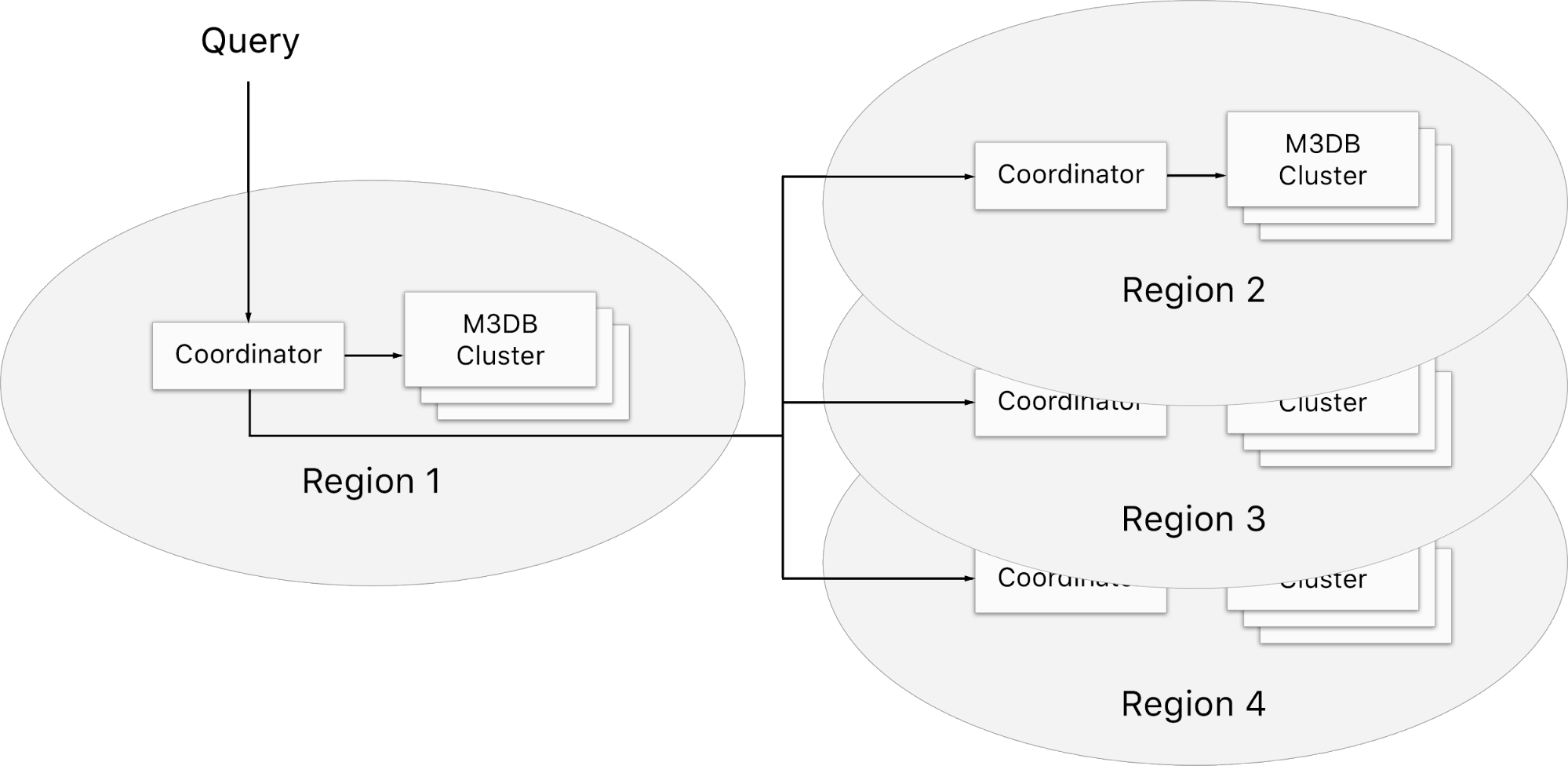
M3
M3是Uber开源的基于M3DB的指标平台,它提供了如下的功能
- 全局数据查询和存储
- 提供数据聚合以及保留(retention)功能
- 可作为prometheus的存储后台,提供prometheus的高可用部署

Prometheus实践
recording rule
生成recording rule
groups:
- name: test
rules:
- record: job:prometheus_http_response_size_bytes_sum:sum
expr: sum(prometheus_http_response_size_bytes_sum) by (job)
在graph中查看recording rule生成的指标
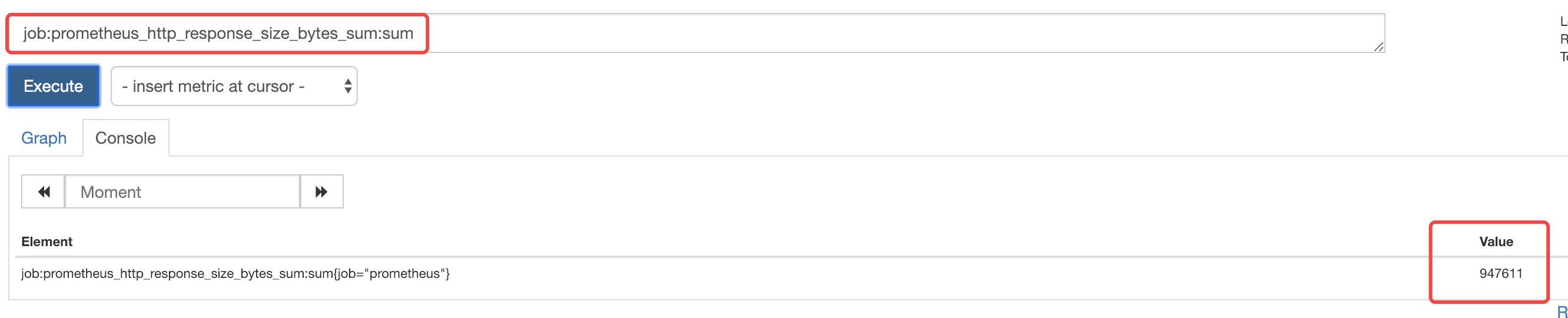
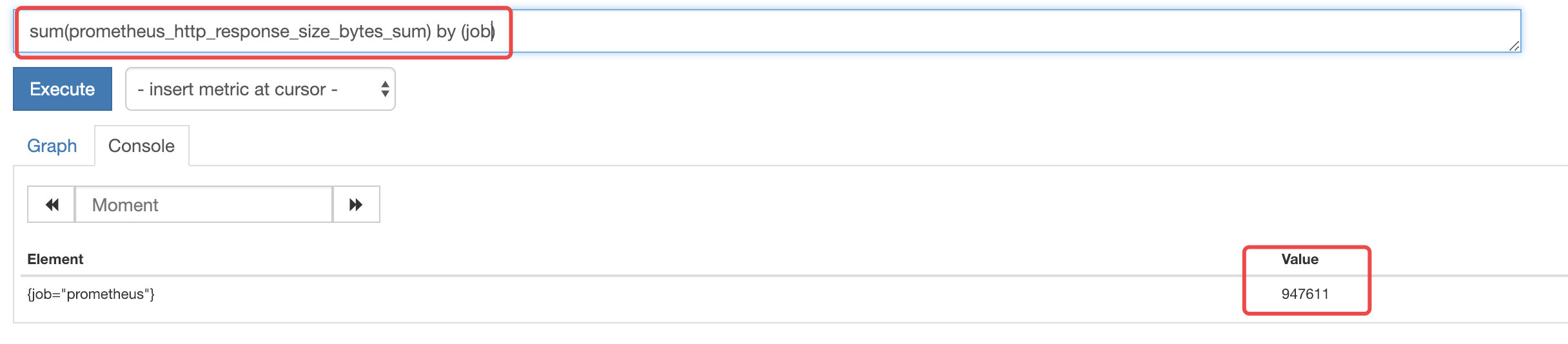
可以看到生成的新指标与表达式得到的指标值一致
remote_write/remote_read
influxdb
influxdb内部已经实现了读写prometheus数据的协议,只需要在prometheus.yml中配置remote_write和remote_read的url地址即可
remote_write:
- url: "http://127.0.0.1:8086/api/v1/prom/write?db=prometheus_test"
remote_read:
- url: "http://127.0.0.1:8086/api/v1/prom/read?db=prometheus_test"
配置prometheus之后,需要在infludb中创建配置中对应的数据库
create database prometheus_test
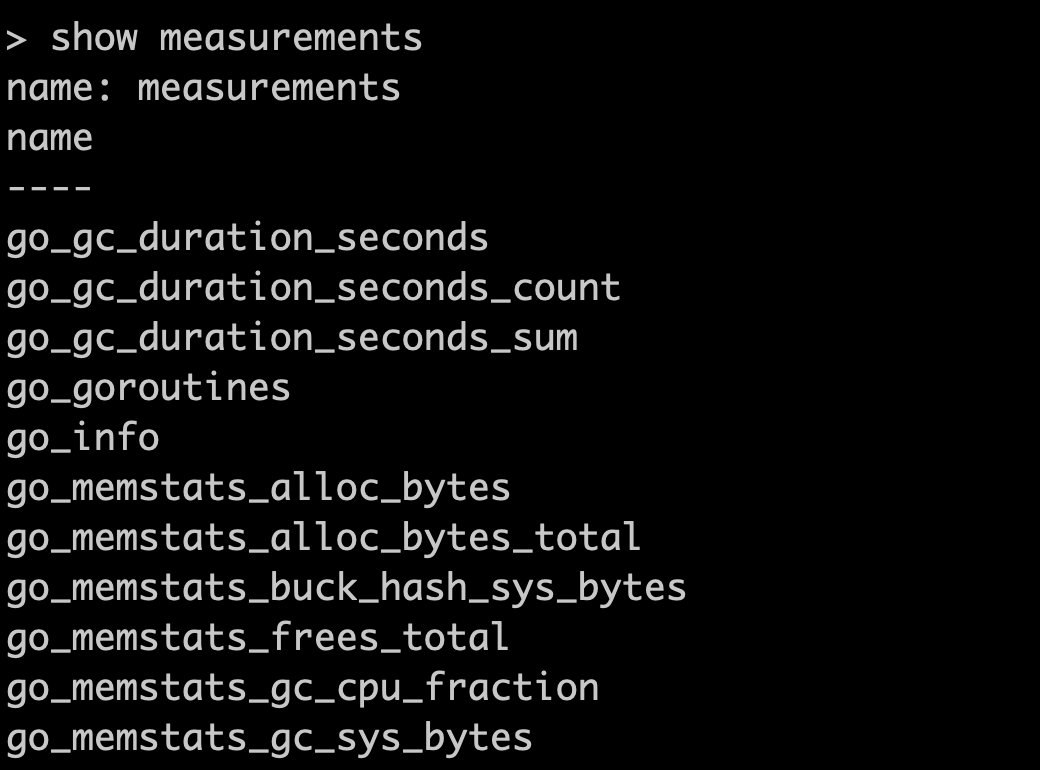
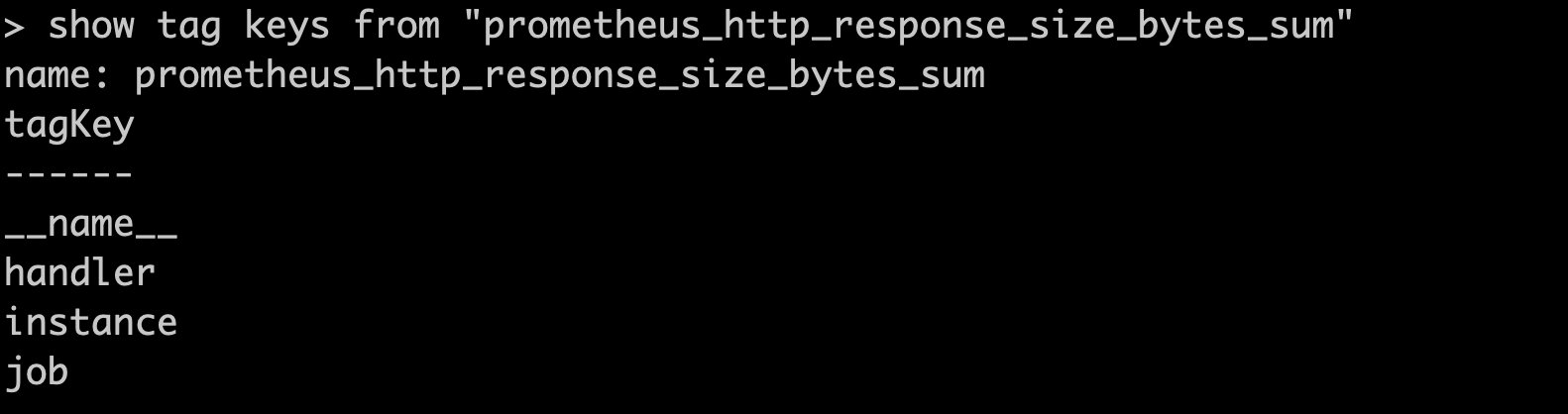
启动prometheus之后,可以在influxdb中看到生成的measurement,每个metric对应一个measurement,而metric中的label对应inflxudb的tag
# Prometheus metric
example_metric{queue="0:http://example:8086/api/v1/prom/write?db=prometheus",le="0.005"} 308
# Same metric parsed into InfluxDB
measurement
example_metric
tags
queue = "0:http://example:8086/api/v1/prom/write?db=prometheus"
le = "0.005"
job = "prometheus"
instance = "localhost:9090"
__name__ = "example_metric"
fields
value = 308
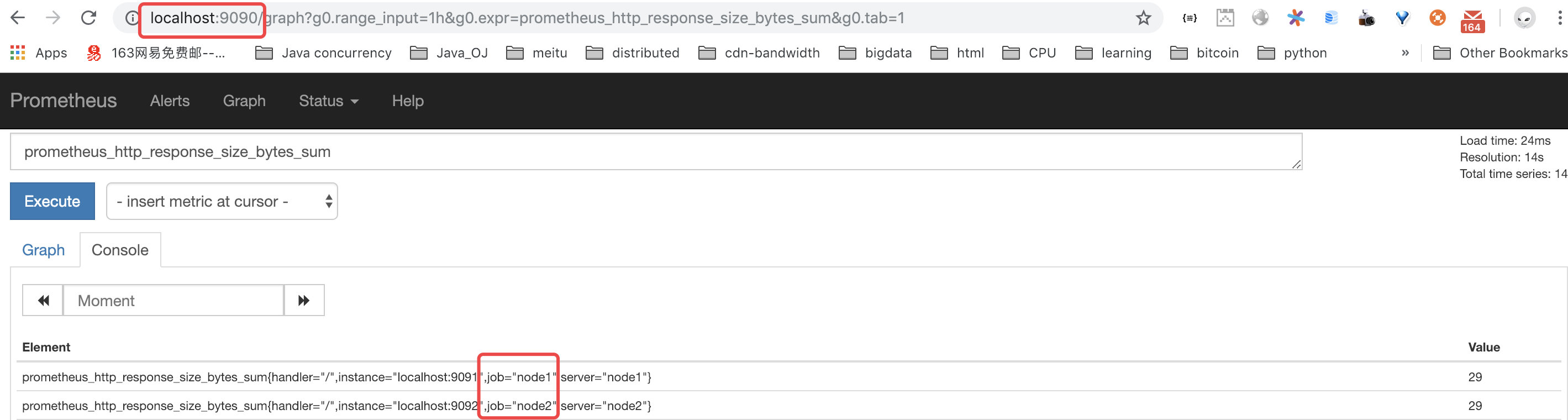
federation
启动三台prometheus server,其中一台作为master,从另外两台拉取数据
| name | role | port |
|---|---|---|
| prometheus | master | 9090 |
| node1 | collector | 9091 |
| node2 | collector | 9092 |
master配置
global:
scrape_interval: 15s
evaluation_interval: 15s
scrape_configs:
- job_name: 'prometheus'
honor_labels: true
metrics_path: '/federate'
params:
'match[]':
- '{job="node1"}'
- '{job="node2"}'
node1配置
global:
scrape_interval: 15s
evaluation_interval: 15s
external_labels:
server: 'node1'
scrape_configs:
- job_name: 'node1'
static_configs:
- targets: ['localhost:9091']
node2配置
global:
scrape_interval: 15s
evaluation_interval: 15s
external_labels:
server: 'node2'
scrape_configs:
- job_name: 'node2'
static_configs:
- targets: ['localhost:9092']
启动3台prometheus
#master
./prometheus --config.file=prometheus.yml
#node1
./prometheus --config.file=prometheus-node1-9091.yml --storage.tsdb.path=data-node1 --web.listen-address=0.0.0.0:9091
#node2
./prometheus --config.file=prometheus-node2-9092.yml --storage.tsdb.path=data-node2 --web.listen-address=0.0.0.0:9092
可以看到在master可以查询到另外两台node的数据