在一个高性能的网络服务中,一个进程往往需要同时处理多个socket。在上一篇博客Linux IO模型中提到的IO多路复用模型就是为了解决这个问题的。
Select,Poll,EPoll是IO多路复用的三种机制,下面来具体看下三者之间的联系和区别
Select
刚刚也说了IO多路复用模型是为了监视多个socket,显而易见,最简单的做法就是为维护一个socket列表,表示进程需要监视的socket。如果列表中的socket都没有数据,那么进程将被挂起;如果有一个以上的socket接收到数据,那么就唤起进程,进程遍历socket列表以便找出接收到数据的socket。
int fds[] = 存放需要监听的socket;
while(1){
//1. 检测是否有socket接收到数据
int n = select(..., fds, ...)
//2. 遍历列表,找出接收到数据的socket
for(int i=0; i < fds.count; i++){
if(FD_ISSET(fds[i], ...)){
//fds[i]的数据处理
}
}
}
可以看到select的工作机制很简单,主要是两步
- 监视socket列表,如果收到数据则返回,否则阻塞进程
- 遍历socket列表,找出接收到数据的socket
因此我们可以知道select的效率不高,原因是显而易见的,select每次都要遍历列表才知道哪些socket接收到数据。另一方面,一个进程能够监视的文件描述符(fds)有限制,最大一般是1024,也就是说select最多只能同时监视1024个socket
//select函数定义
int select (int n, fd_set *readfds, fd_set *writefds, fd_set *exceptfds, struct timeval *timeout);
总结一下,select存在的问题
- 被监控的fds集合大小被限制了1024,不够用
- fds集合需要从用户空间拷贝到内核空间的问题,耗费性能
- 需要遍历fds集合才能知道有数据接收的fds列表
Poll
Poll是为解决select的第一个问题
int poll (struct pollfd *fds, unsigned int nfds, int timeout);
poll不在用三个fds集合,而是使用一个pollfd的指针,指针指向了需要监视的fds,因此poll并没有最大数据量限制,但是它的性能同样不高,因为它没有解决select的第二,第三个问题。
EPoll
Epoll解决了select遗漏的第2,3个问题,主要的思路有两点
- 功能分离,select中维护等待队列(socket列表)和阻塞进程两个步骤结合在一起了,对于频繁调用select的进程来说,socket列表变化的可能性很小,基本固定,并不需要每次都修改。EPoll将两个操作分开。
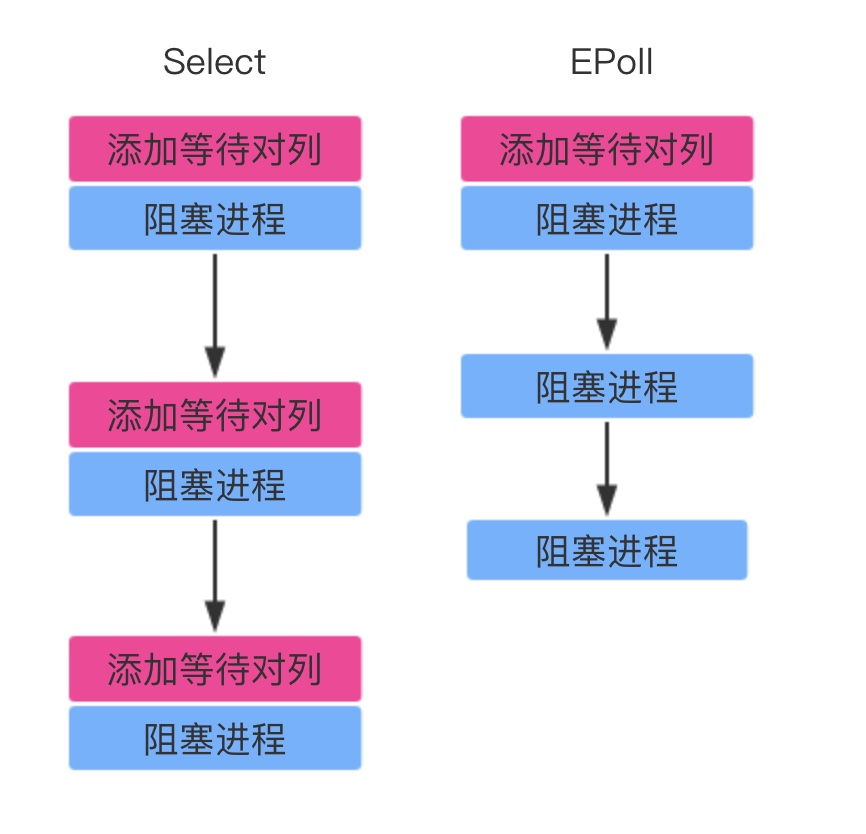
- 维护就绪列表,select低效的另一个原因在于程序不知道哪些socket收到数据,只能一个个遍历。如果内核维护一个“就绪列表”,引用收到数据的 socket,就能避免遍历。
EPoll操作流程
EPoll操作中涉及三个接口
int epoll_create(int size)
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
int epoll_wait(int epfd, struct epoll_event * events, int maxevents, int timeout);
- epoll_create创建了eventpoll对象,用来维护就绪列表
- epoll_ctl用来维护监视列表,可以添加或删除所要监听的 socket
- 当调用epoll_wait时,如果就绪列表中存在socket,则直接返回,如果没有,则阻塞进程
可以看到epoll高效原因,主要是维护了两个队列,一个是监视队列,一个是就绪队列。监视队列解决了select中fds频繁拷贝的问题,就绪队列解决了select中需要遍历列表才能知道哪个socket接收到数据的问题



