CMS定义
CMS的全称是Concurrent Mark Sweep。
从名称上可以看出CMS的特点,可并发,使用标记-清除算法。CMS是针对老年代垃圾回收的收集器
CMS目标
CMS设计时的目标就是获取最小的停顿时间,也就是低延迟。对于响应时间比较敏感的应用比较适合使用CMS
CMS过程
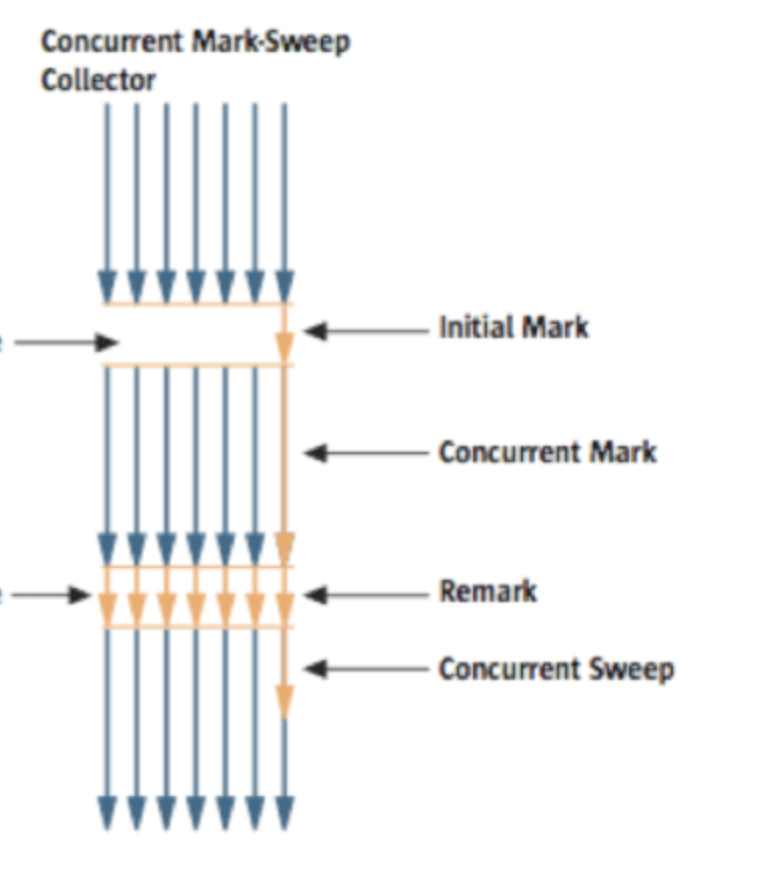
CMS的执行过程可以分为以下几个阶段
- Initial Mark(STW)
- Concurrent Mark
- Concurrent Preclean
- Final Remark(STW)
- Concurrent Sweep
- Reset
Initial Mark(初始标记)
在这个阶段会进行可达性分析,因此需要Stop the world,暂停应用程序。
初始标记仅仅标记两类对象,因此速度很多,STW的时间很短
- GC ROOT直接关联的对象
- 新生代引用的老年代对象
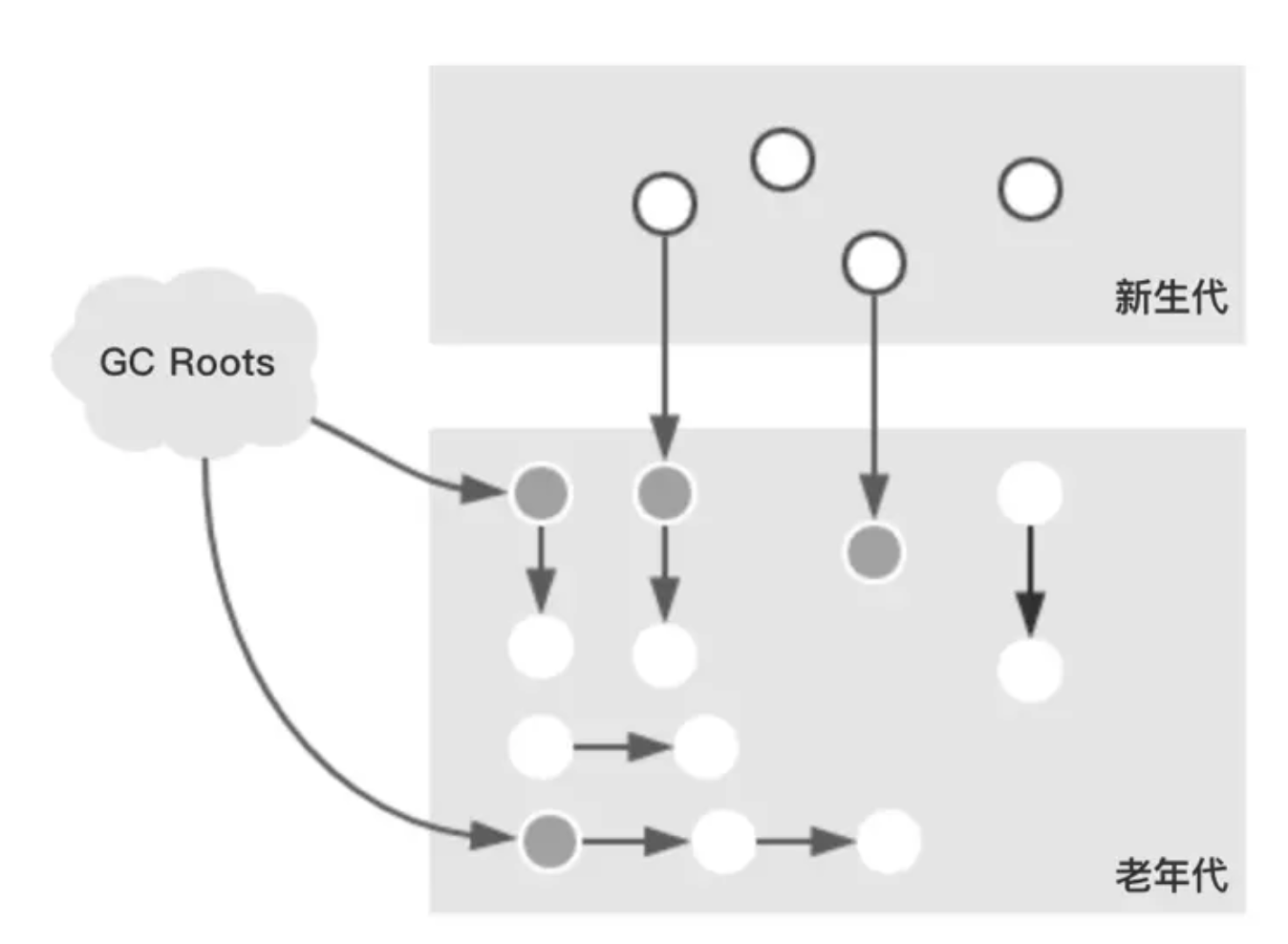
Concurrent Mark(并发标记)
在这个阶段GC线程与用户并发进行,从初始标记阶段标记的对象出发,标记所有可达的对象。
Concurrent Preclean(并发预清理)
由于Concurrent Mark阶段是应用线程和GC线程并发执行的,那么在这个期间,可能会有对象从新生代晋升到老年代,也有一些引用会发生改变,所有在这个阶段会标记新生代晋升的对象、新分配到老年代的对象以及在并发阶段被修改了的对象
我们知道CMS的目标是获取最短的停顿时间,如果不在这个阶段进行这些标记,那么下一个remark阶段就需要更多的工作,而这个阶段是需要STW,因此要把一些复杂的操作在预清理阶段完成。
归根结底,在这个阶段主要处理一个问题
- 如何确定老年代的对象是活着的
答案也很简单,通过GC ROOT可达的对象就是活着的,因此需要扫描新生代和老年代。但是全量扫描新生代和老年代肯定会非常耗时,因此需要一个能够快速识别新生代和老年代活着对象的机制。
新生代识别活着对象
对于新生代来说,经过一次Young GC后剩下的对象肯定都是活着的,并且活着的对象很少。
可想而知,如果在扫描新生代之前发生一次Young GC,那么扫描的效率将大大提高。
CMS有两个参数:
- CMSScheduleRemarkEdenSizeThreshold 默认2M
- CMSScheduleRemarkEdenPenetration 默认值50%
这两个参数的意思,在Eden空间的大小超过2M时,启动可中断的并发预清理(CMS-concurrent-abortable-preclean), 直到Eden的空间利用率超过50%时中断,进入到下一个阶段(remark)。
可中断的并发预清理是为了等待一次Young GC的发生,但是我们知道这个是不可控的,因此需要控制这个阶段的执行时间,CMS通过以下两个参数来控制
- CMSMaxAbortablePrecleanLoops 可中断的并发预清理的执行次数超过这个值,默认是0
- CMSMaxAbortablePrecleanTime 执行可中断的并发预清理的时间超过这个值,默认是5S
另外CMS还提供了CMSScavengeBeforeRemark参数,使在进入remark阶段之前强制执行一次Young GC。
老年代识别活着对象
老年代会维护一个叫CARD TABLE的数组,数组中每个位置存的是个byte,CMS将老年代的空间分成512bytes的块,card table中的每一个元素对应一块。
在并发标记阶段,如果某个对象的引用发生了变化,那么就标记这个对象所在的块为dirty card。
在并发预清理阶段就会重新扫描这个块,将该对象引用的对象标记为可达。
card table还有一个作用,如果一个老年代对象引用了新生代的对象,那么它对应的块也会被标记为dirty card,这样在Young GC阶段通过扫描card table就可以快速识别老年代引用的对象
Final Remark(重新标记)
暂停所有应用线程,重新扫描堆中的对象,进行可达性分析,标记活着的对象。注意这个阶段是多线程的
Concurrent Sweep(并发清理)
应用线程被激活,同时清理哪些无效的对象
Reset(重置)
CMS清除内部状态,为下次回收做准备
CMS存在的问题
1. 抢占CPU资源
CMS是并发的,而并发就意味着CPU资源,即GC线程与应用线程抢占CPU,这样可能会造成应用执行效率下降。
CMS默认的回收线程数是(CPU个数+3)/4,可以看到如果CPU个数为2,CMS会启动一个GC线程,相当于GC线程占用了50%的CPU资源。
但是对于目前的场景来说,PC至少都是双核处理器,更别说大型的服务器了。
2. Concurrent Mode Failure
由于并发清理阶段,用户线程还在运行,所以必须预留出一定的空间提供给用户线程,不能像其他收集器那样等到老年代满了在进行GC。
CMS提供了CMSInitiatingOccupancyFraction参数来设置老年代空间使用百分比,达到了百分比就进行垃圾回收,默认值是92%。
可以想象,如果这个参数设置过小,那么就会导致频繁的GC,如果设置的过高呢?假设将参数设置为99%,若用户线程所需的空间大于1%,那么就会产生Concurrent Mode Failure,意思是并发模式失败了。
这时,虚拟机就会启动备案:使用Serial Old收集器重新对老年代进行垃圾回收.如此一来,停顿时间变得更长
CMS还提供了动态检测机制,可以根据历史记录,来预测老年代还要多久填满以及进行一次回收所需的时间。这个特性可用通过UseCMSInitiatingOccupancyOnly来关闭
3. Floating Garbage
在并发清理阶段,用户线程还在运行,那么就有可能产生新的垃圾,新的垃圾在此次GC无法清除,只能等到下次GC处理,这些垃圾就成为Floating Garbage(浮动垃圾)
4. 空间碎片
CMS使用的是mark-sweep算法,可能会造成大量的空间碎片,空间碎片过多,会导致无法分配大对象,此时就不得不进行一次full gc
CMS的解决方案是使用UseCMSCompactAtFullCollection参数(默认开启),在顶不住要进行Full GC时开启内存碎片整理
同时还有另外一个参数CMSFullGCsBeforeCompaction,用于设置执行多少次不压缩的Full GC后,跟着来一次带压缩的(默认为0,每次进入Full GC时都进行碎片整理)。
相关参数
| 参数 | 默认值 | 说明 |
|---|---|---|
| UseConcMarkSweepGC | 使用CMS | |
| CMSScheduleRemarkEdenSizeThreshold | 2M | Eden空间大于2M,则开启可中断并发预清理 |
| CMSScheduleRemarkEdenPenetration | 50% | Eden空间利用率大于50%,则中断预清理,进入remark |
| CMSMaxAbortablePrecleanLoops | 0 | 执行可中断预清理的次数超过阈值,则进入remark |
| CMSMaxAbortablePrecleanTime | 5S | 执行可中断预清理的时间超过5秒,则进入remark |
| CMSInitiatingOccupancyFraction | 92% | 老年代空间利用率达到92%,则进行GC |
| UseCMSInitiatingOccupancyOnly | true | 是否开启自动预测GC时机 |
| UseCMSCompactAtFullCollection | true | 是否在full gc时进行碎片整理 |
| CMSFullGCsBeforeCompaction | 0 | 执行几次不压缩的full gc后,执行一次带压缩的full gc |



